Технические характеристики AMD RX 6800

Хотя RX 6800 XT позиционируется, как конкурент RTX 3080, с AMD RX 6800 дела обстоят немного иначе.
В Европе 6800 стоит на 60 евро дороже, чем RTX 3070, однако мы ожидаем от карты более высокую производительность.
В этом обзоре мы тестируем RX 6800, уделяя внимание ее характеристикам и новым технологиям
Технические характеристики AMD RX 6800
RX 6800 по-прежнему изготовлен на 7-нм техпроцессе TSMC, как и серия RX 5000, Navi 21 имеет гораздо больший кристалл GPU - 519 мм².
RX 6800 содержит 60 вычислительных блоков (CU) с 64 потоковыми процессорами, что дает в общей сложности 3840 шейдеров.

Номинальная тактовая частота серии RX 6000 значительно увеличилась. Однако RX 6800 работает не так быстро, как RX 6800 XT, с game clock 1815 MHz и бустом до 2105 MHz. Для сравнения: RX 5700 XT имеет game clock 1755 MHz.
AMD также увеличила объем памяти, установив 16 ГБ памяти GDDR6 в каждой модели RX 6000 (пока что).
Память имеет тактовую частоту 16 Gbps и работает через 256-битный интерфейс памяти с общей пропускной способностью 512 GB/s.
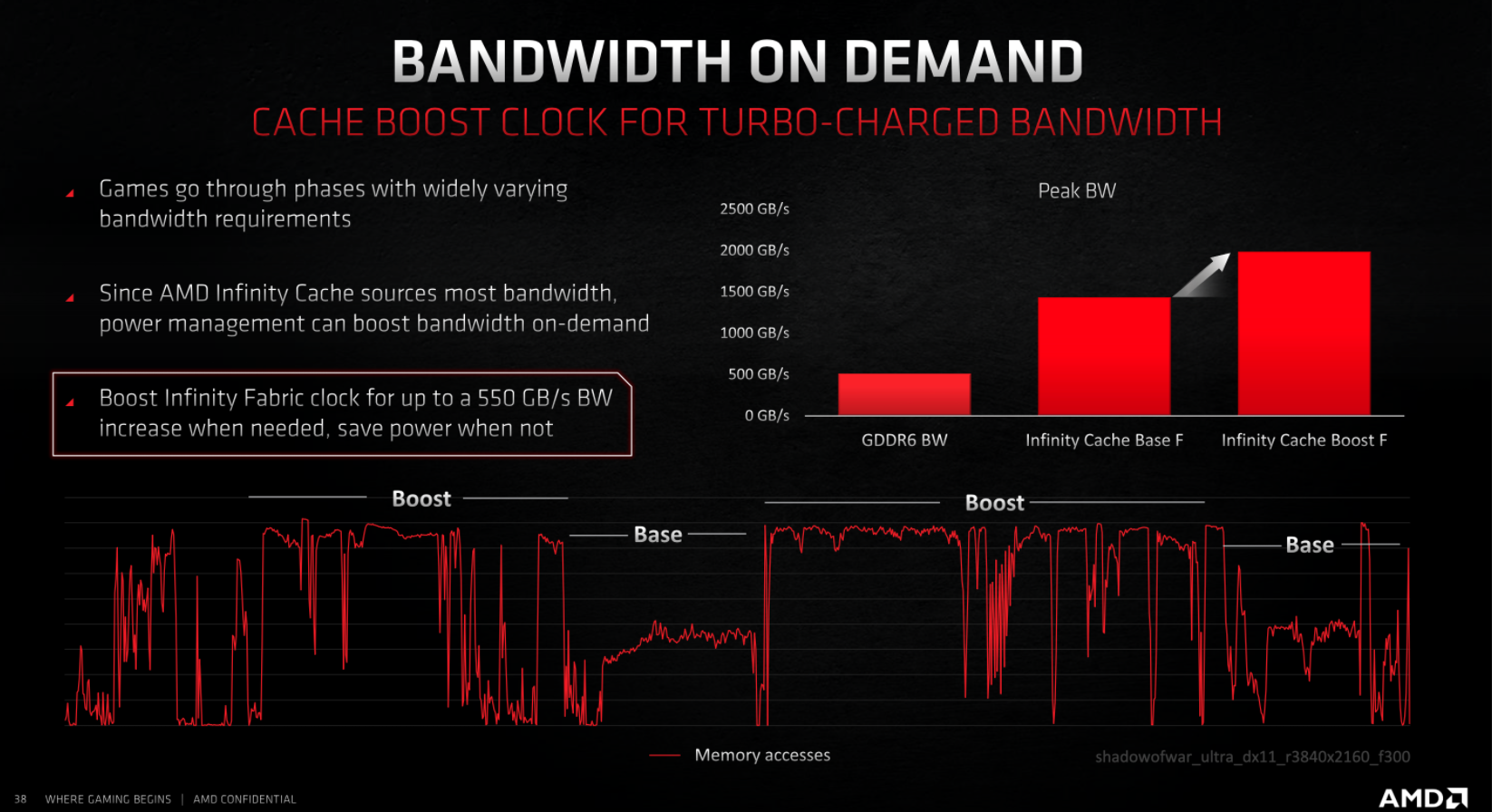
AMD также реализовала кэш-память «Infinity» на 128 МБ для GPU Navi 21, чтобы значительно увеличить эффективную пропускную способность памяти без чрезмерного энергопотребления.
Говоря о мощности, RX 6800 имеет номинальную общую мощность (TBP) 250 Вт, что на 25 Вт больше, чем у RX 5700 XT.
RDNA 2
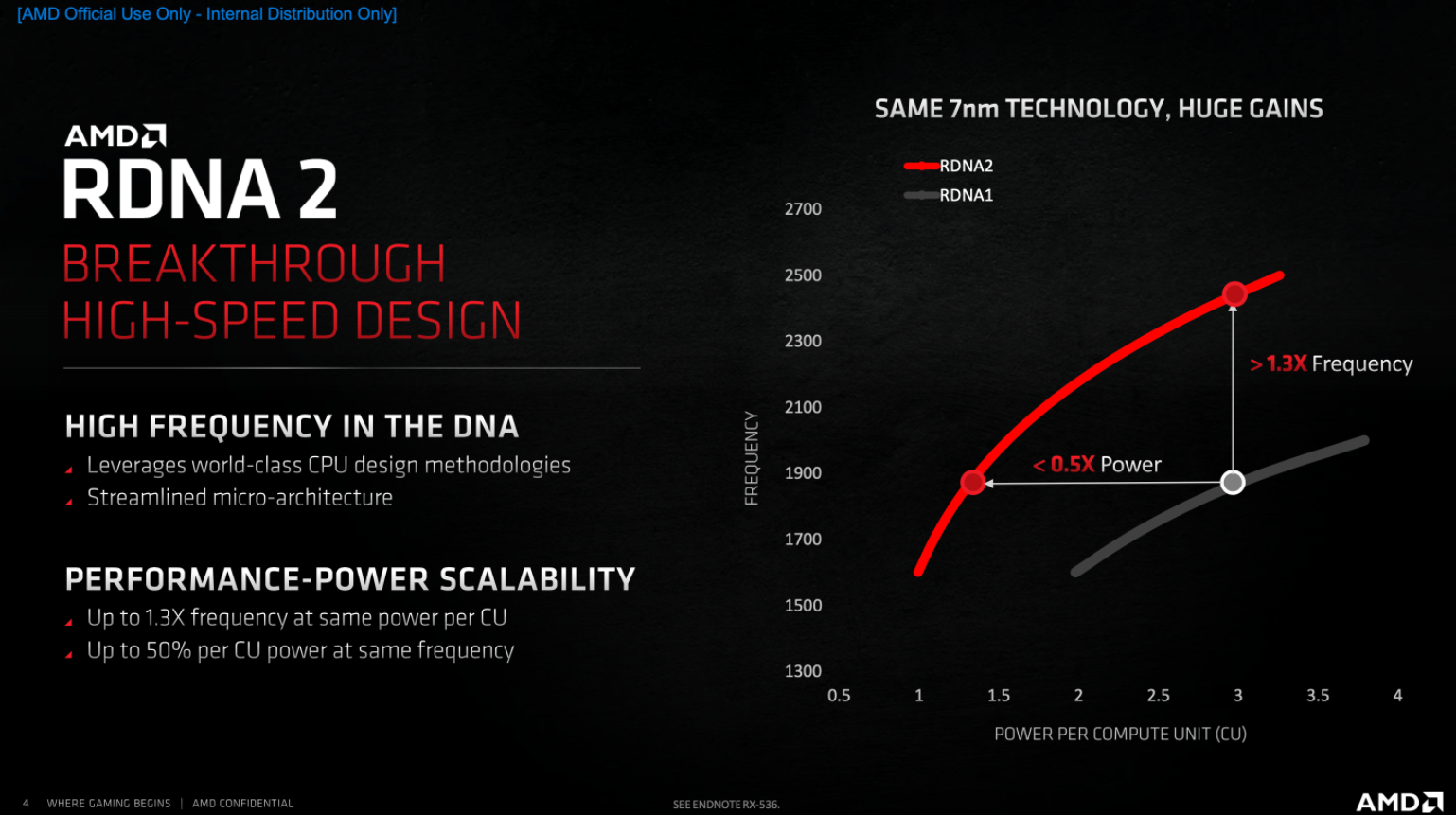
С RDNA 2 AMD заявляет, что была введена методология проектирования от команды Zen CPU, одновременно «оптимизируя микроархитектуру для достижения рекордных частот».
Частично это происходит в результате оптимизации частот во всем диапазоне напряжений для повышения масштабируемости.
AMD заявляет, что это позволяет RDNA 2 иметь на 30% большую частоту при той же мощности CU по сравнению с RDNA или снижать мощность примерно на 50% на той же частоте.


Майкл Мантор, главный разработчик GPU AMD, говорит:
«Такой уровень увеличения и снижения энергопотребления в рамках той же технологии процесса позволил нам удвоить количество CU у Big Navi при небольшом увеличении мощности».
Частично это является результатом огромных изменений, которые, по заявлению AMD, претерпела RDNA 2 CU для достижения заявленной на 30% более высокой производительности при той же мощности по сравнению с RDNA.
Компания подчеркивает, какое влияние машинное обучение может внести в игры, в результате чего в проект были включены различные операции с разной точностью, чтобы ускорить эти рабочие нагрузки ИИ.
Трассировка лучей Ray Accelerator
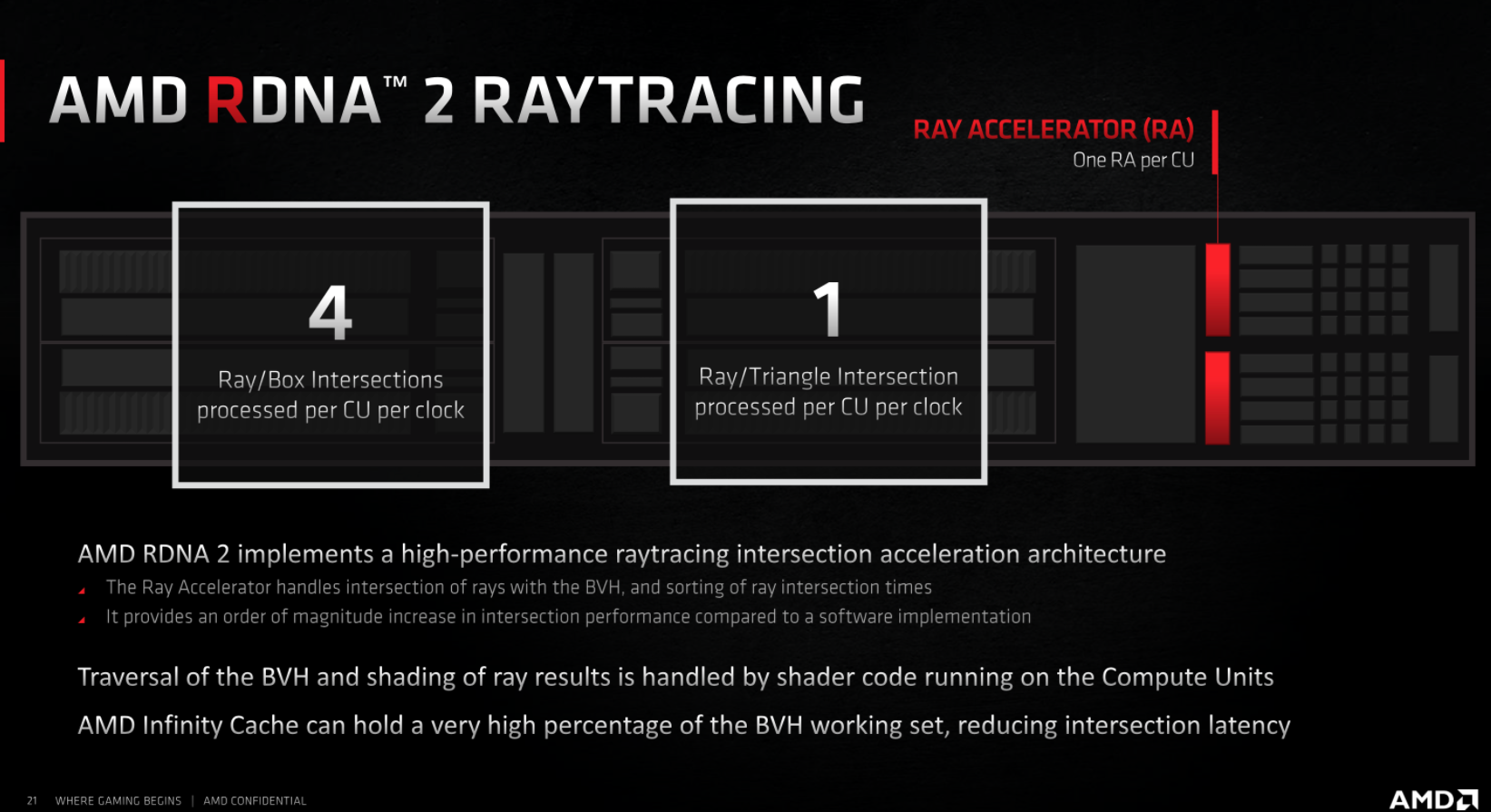
Каждый CU теперь является домом для одного Ray Accelerator (ускоритель лучей), оборудования, отвечающего за обработку пересечения лучей с помощью Bounding Volume Hierarchy (BVH).
AMD заявляет, что Ray Accelerator может рассчитывать до 4 пересечений лучей / прямоугольников или пересечений лучей / треугольников за каждый такт, и в целом предлагает примерно в 10 раз более высокую производительность трассировки лучей, чем те, которые могли бы достичь только шейдеры.
Мы спросили AMD, чем Ray Accelerator отличается от Nvidia RT Core, и дословно скопировали их ответ:
«По сравнению с полностью выделенными ядрами для трассировки лучей Nvidia, ускорители лучей RDNA 2 тесно интегрированы в RDNA 2 CU, используя большую часть существующего оборудования, которое обычно не используется во время проходов трассировки лучей.
Окончательные характеристики производительности будут зависеть от игры, типа используемых эффектов трассировки лучей и оптимизаций. Однако мы считаем, что наши ускорители лучей вместе с другими улучшениями RDNA 2, такими как увеличение частоты, увеличение количества CU и Infinity Cache, помогут обеспечить визуально больший игровой процесс как с трассировкой лучей, так и без нее в исходных разрешениях».
AMD Infinity Cache

Infinity Cache также привлекла много внимания. AMD реализовала это решение, чтобы обеспечить достаточную пропускную способность для увеличенного количества CU, работая на более высоких частотах, поскольку, по их утверждениям, эти два изменения в противном случае потребовали бы увеличения пропускной способности в 2,6 раза без истощения GPU - что, по их утверждению, было бы крайне непрактичным из-за физических размеров и требования к мощности.
Каждый из 16 каналов в Infinity Fabric обеспечивает 64 B данных за такт, обеспечивая передачу 1024 B данных за такт на частоте до 1,94 GHz.
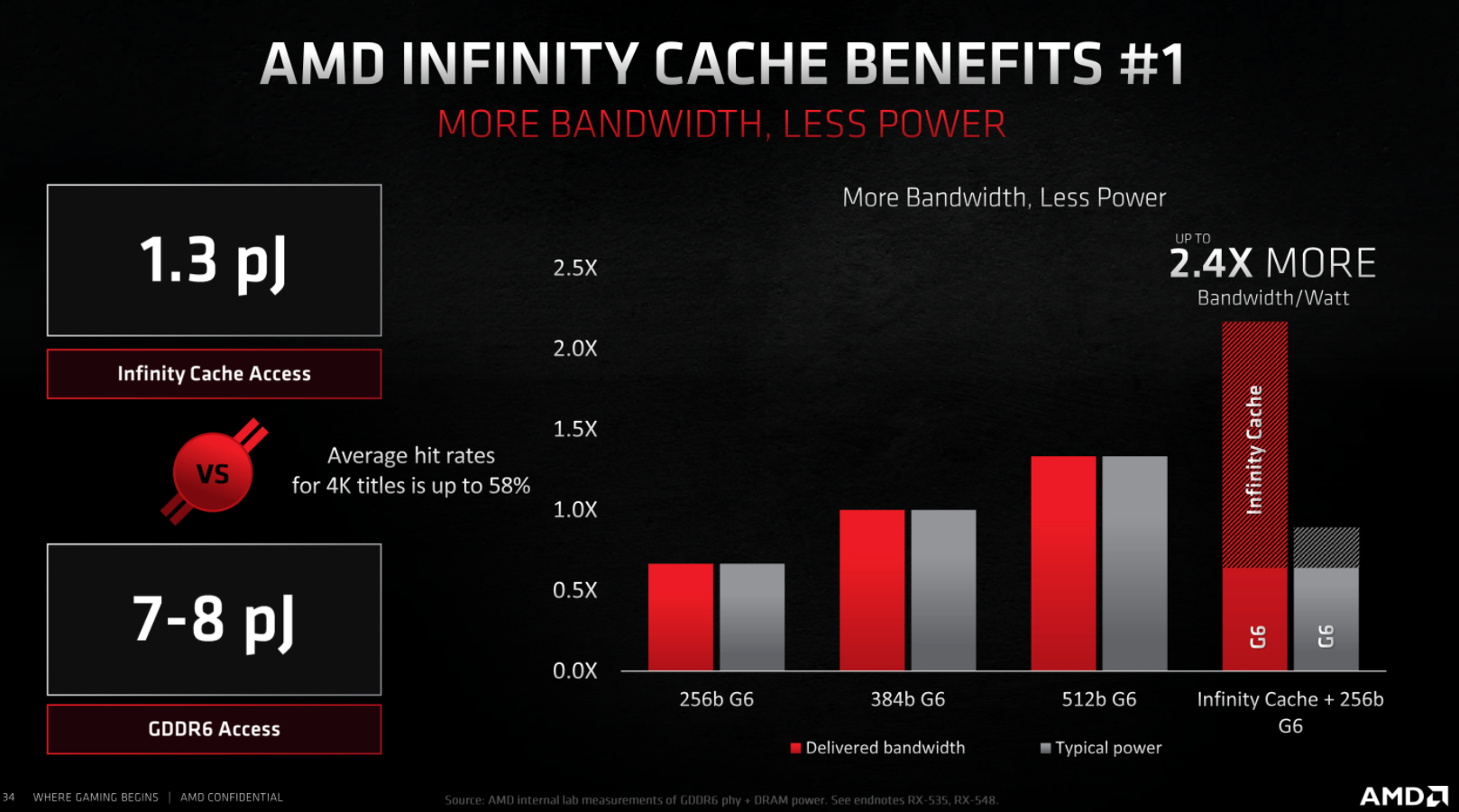
Наффцигер (разработчик AMD) утверждает, что это в 4 раза превышает пропускную способность существующих решений GDDR6 и обеспечивает достаточную пропускную способность для движка.
AMD заявляет, что с этим встроенным кешем может отображать кадры с меньшим энергопотреблением на бит по сравнению с решением, обеспечивающим эквивалентную пропускную способность традиционными средствами.

AMD утверждает, что с Infinity Cache она может обеспечить более чем в два раза большую пропускную способность, чем 384-битный интерфейс GDDR6, с минимальным увеличением мощности. В целом компания заявляет, что пропускная способность на ватт увеличилась в 2,4 раза.

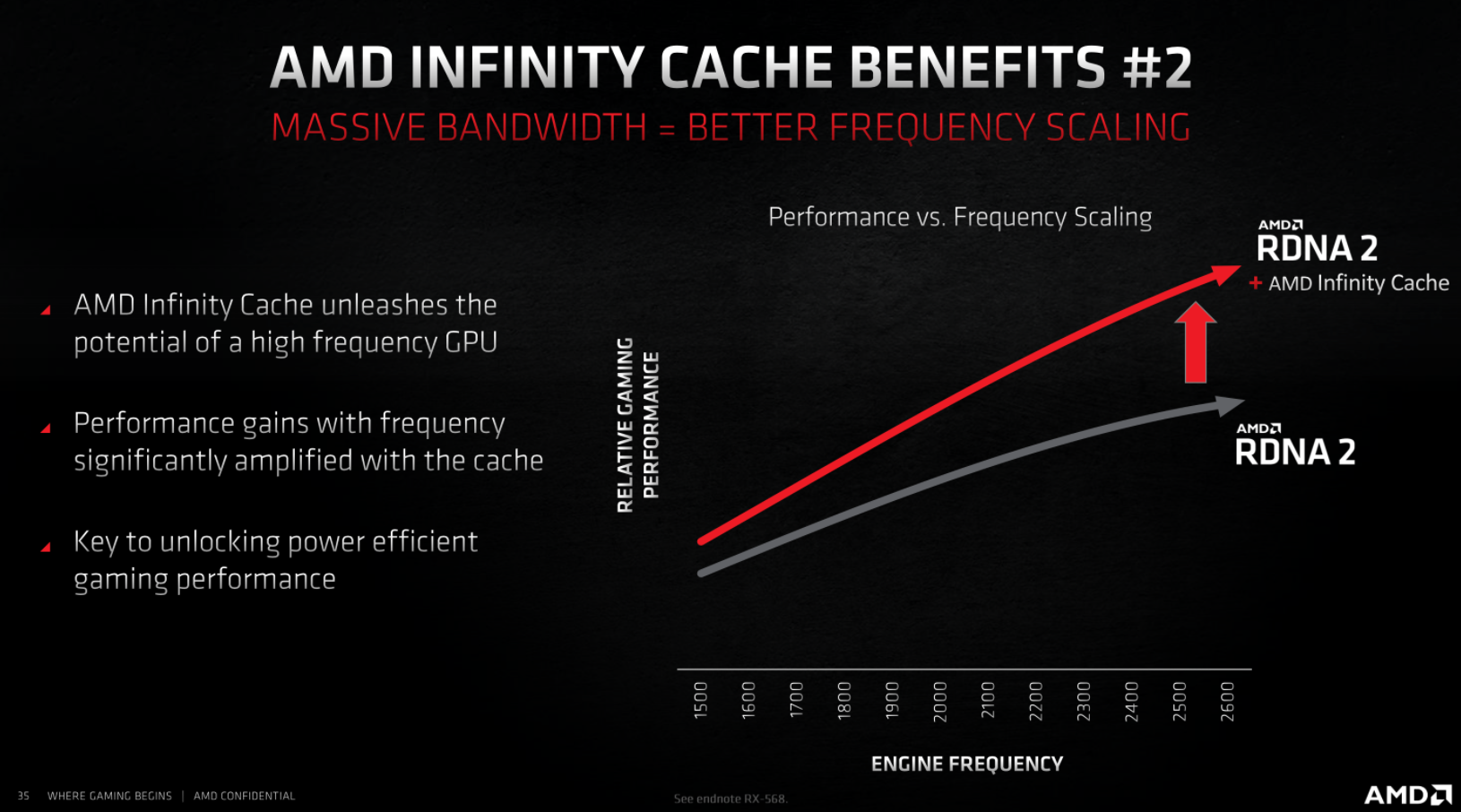
Кроме того, Infinity Cache позволяет AMD лучше масштабировать свою производительность за счет увеличения частоты GPU.
Без Infinity Cache относительный выигрыш от увеличения тактовой частоты ядра значительно уменьшается на более высоких частотах.
Smart Access

Также мы поговорим о памяти Smart Access. Об этом недавно стало известно в новостях, так как Nvidia заявила, что работает над внедрением той же технологии.
Для AMD Smart Access Memory (SAM) относится к возможностям лучшего доступа к GPU VRAM.
В настоящее время CPU имеет доступ только к 256 МБ памяти GPU одновременно, но с CPU серии Ryzen 5000, с материнскими платами серии 500 и с GPU серии RX 6000, компания AMD сняла это ограничение – теперь процессор имеет полный доступ к высокоскоростной памяти GPU.

Сейчас смотрят
































