Характеристики 3090, 3080, 3070. Подробное сравнение с 2080 (и 2080TI)

Характеристики и сравнение 30 линейки с 20
Можно с уверенностью сказать, что серия RTX 20 никогда особо не привлекала игровую и майнинг аудиторию, чего пыталась достичь Nvidia.
Несмотря на то, что архитектура Turing обеспечивает поддержку аппаратного-ускорения трассировки лучей и технологии «Deep Learning Super Sampling» (DLSS) на основе искусственного интеллекта, мы все равно видели относительно скромный выигрыш с точки зрения традиционной производительности - в сочетании с более высокими ценами (на 20-ю линейку) по сравнению с 10 линейкой – означало, что большинство геймеров и майнеров не стремились к обновлению и использовали свои старые видеокарты.
С Ampere Nvidia пытается решить эту проблему. Количество ядер было значительно увеличено по всем направлениям: RTX 3090 может похвастаться невероятными 10496 ядрами CUDA, а RTX 3080 - 8704.
Память также была обновлена до новой GDDR6X от Micron, которая в сочетании с более широким 320-битным интерфейсом памяти обеспечивает почти на 70% более высокую пропускную способность, чем RTX 2080.
Благодаря переходу на 8-нм узел Samsung, GPU RTX 3080 также оснащен впечатляющими 28 миллиардами транзисторов.
Компания также продолжила развивать свои функции RTX, заявляя о значительном улучшении производительности ядер RT и Tensor по сравнению с Turing.
Можно с уверенностью сказать, что прием технологии RTX в целом был довольно прохладным (со стороны потребителей), но с запуском DLSS 2.0 в апреле и ядрами RT 2-го поколения от Nvidia, которые предположительно увеличивают пропускную способность в два раза по сравнению с ядрами первого поколения, Ampere может изменить мнение потребителей.
Все эти улучшения сопровождаются повышенным энергопотреблением, несмотря на то, что Nvidia перешла с 12-нанометрового техпроцесса TSMC на 8-нанометровый технологический узел Samsung в 30-й серии.
Общая графическая мощность или TGP - энергопотребление всей карты - теперь составляет до 320 Вт для RTX 3080, что на 28% больше, чем у флагмана последнего поколения, RTX 2080 Ti.
Несмотря на это, мы также можем отметить, что Clock Speed был немного снижен по сравнению с 20-й серией, при этом RTX 3080 имеет Boost Clock 1710 MHz, по сравнению с Clock Speed 1815 MHz у RTX 2080 Super.
Ampere вносит несколько ключевых изменений в архитектуру GPU и далее мы о них поговорим!
Новый SM в картах Nvidia 30 серии
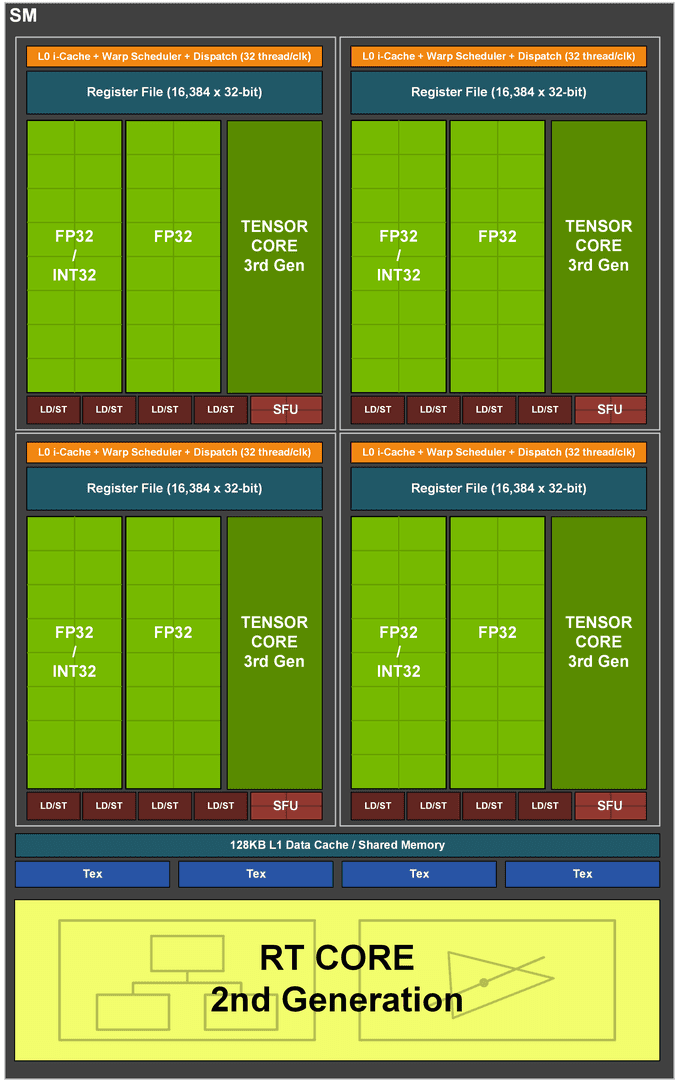
Одной из самых ярких особенностей RTX 30-й серии было невероятно высокое количество ядер. Учитывая, что RTX 2080 Ti, выпущенный с 4352 ядрами CUDA, был самым загруженным из стека GeForce 20-й серии, было довольно удивительно видеть, что даже RTX 3070 превосходит этот показатель, а RTX 3080 так вообще имеет вдвое больше ядер.
Это результат того, что Nvidia удвоила количество FP32 ALU на SM. Если у Turing был выделенный путь к данным для операций INT, то с Ampere он теперь разделен между INT и FP32.
Tony Tamasi, вице-президент по техническому маркетингу в Nvidia, объяснил это изменение (на Reddit):
«Одной из ключевых целей разработки SM Ampere 30-й серии было достижение вдвое большей производительности для операций FP32 по сравнению с Turing SM. Для достижения этой цели Ampere SM включает новые конструкции каналов данных для операций FP32 и INT32.
Один канал данных в каждом разделе состоит из 16 ядер CUDA FP32, способных выполнять 16 операций FP32 за такт. Другой путь данных состоит из 16 ядер CUDA FP32 и 16 ядер INT32. В результате этой новой конструкции каждый раздел Ampere SM способен выполнять либо 32 операции FP32 за такт, либо 16 операций FP32 и 16 операций INT32 за такт. Все четыре раздела SM вместе могут выполнять 128 операций FP32 за такт, что вдвое превышает скорость FP32 SM по Turing, или 64 операции FP32 и 64 INT32 за такт.
Удвоение скорости обработки для FP32 повышает производительность для ряда распространенных графических и вычислительных операций и алгоритмов. Современные шейдерные нагрузки обычно содержат смесь арифметических инструкций FP32, таких как FFMA, сложение с плавающей запятой (FADD) или умножение с плавающей запятой (FMUL), в сочетании с более простыми инструкциями, такими как добавление целых чисел для адресации и выборки данных, сравнение с плавающей запятой или min / max для результатов обработки и т. д.
Прирост производительности будет зависеть от уровня шейдера и приложения в зависимости от сочетания инструкций. Шейдеры шумоподавления с трассировкой лучей - хорошие примеры, которым можно значительно улучшить удвоение пропускной способности FP32.
Удвоение математической пропускной способности потребовало удвоения поддерживающих ее путей данных, поэтому Ampere SM также удвоил общую память и производительность кэша L1 для SM. (128 байт / такт на Ampere SM против 64 байтов / такт по Turing). Общая пропускная способность L1 для GeForce RTX 3080 составляет 219 ГБ / с против 116 ГБ / с для GeForce RTX 2080 Super.
Как и предыдущие графические процессоры NVIDIA, Ampere состоит из кластеров обработки графики (GPC), кластеров обработки текстур (TPC), потоковых мультипроцессоров (SM), растровых операторов (ROPS) и контроллеров памяти.
GPC - это доминирующий аппаратный блок высокого уровня, в котором все ключевые графические процессоры находятся внутри GPC. Каждый GPC включает в себя выделенный Raster Engine, а теперь также включает в еще два раздела ROP (каждый раздел содержит восемь блоков ROP), что является новой функцией для GPU NVIDIA Ampere Architecture GA10x.
Более подробную информацию об архитектуре NVIDIA Ampere можно найти в официальном документе NVIDIA Ampere Architecture White Paper, который будет опубликован в ближайшие дни».
Память GDDR6X RTX 3090 3080 307
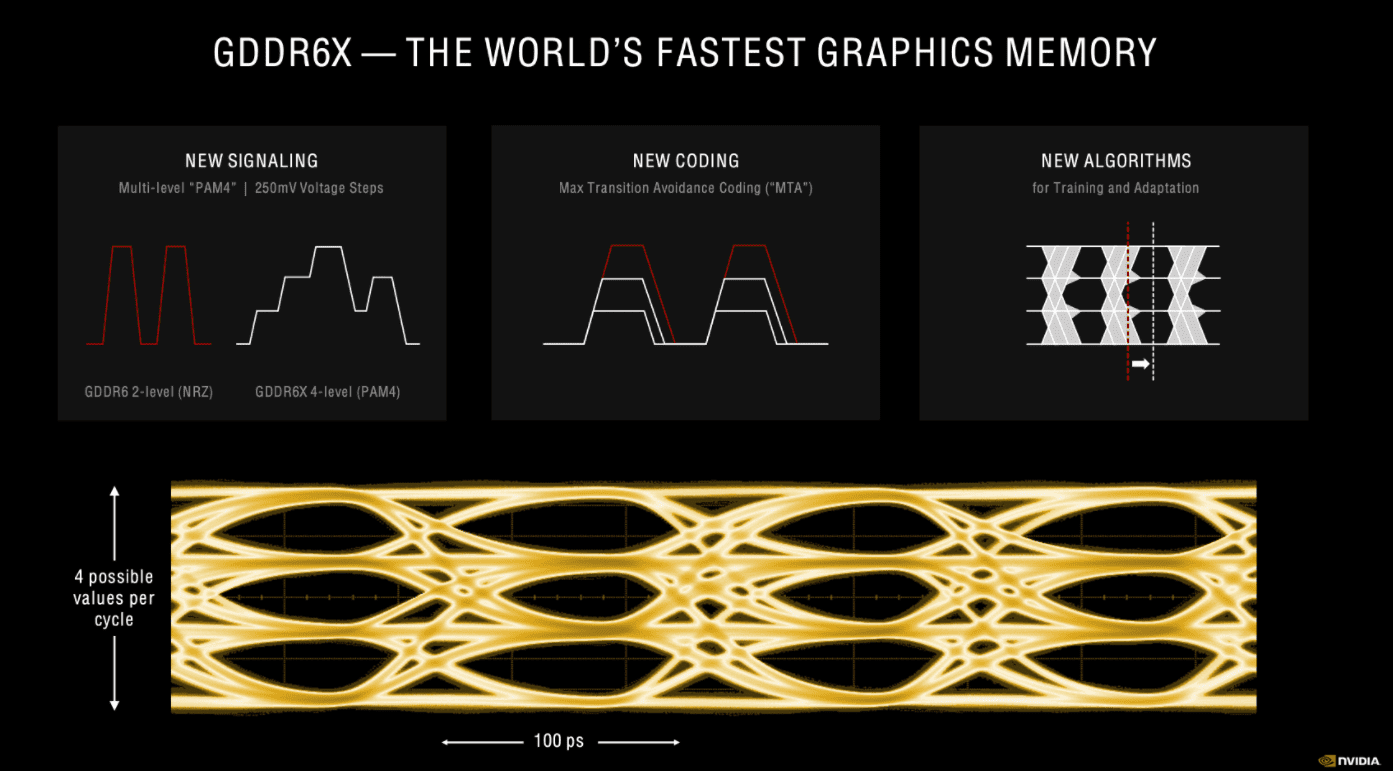
Еще одним шагом вперед является использование памяти GDDR6X в RTX 3080 и RTX 3090, однако RTX 3070 останется на GDDR6. Разработанный в сотрудничестве с Micron, GDDR6X использует новую 4-уровневую импульсную амплитудную модуляцию (PAM4) вместо предыдущей 2-уровневой NRZ, которая используется с GDDR6 (не-X).
Там, где NRZ может отправлять только двоичные данные, PAM4 - как следует из названия - может отправлять один из наших уровней напряжения с шагом 250 mV за такт. Nvidia утверждает, что это позволяет GDDR6X «передавать в два раза больше данных, чем память GDDR6».
RTX 3080 оснащен 10 ГБ памяти GDDR6X с тактовой частотой 19 Gbps. В сочетании с 320-битным интерфейсом памяти пропускная способность памяти достигает 760 ГБ / с, в то время как RTX 3090 способен достигать 936 ГБ / с.
Кроме того, Nvidia изменила реакцию памяти на разгон - как мы увидим позже в обзоре. Nvidia дали официальный ответ по этому поводу:
«Одной из конструктивных особенностей, которые мы добавили для повышения надежности памяти, является обнаружение ошибок транзакций и их воспроизведение.
То есть, когда кодирование показывает, что произошла ошибка передачи данных, передача с ошибкой повторяется или «воспроизводится» до тех пор, пока правильная транзакция с памятью не будет успешной. По мере того, как вы нажимаете на разгон и вызываете больше ошибок, повторные попытки транзакций уменьшают полезную полосу пропускания памяти и, таким образом, снижают производительность.».
Улучшения RT и Tensor

Наряду с улучшениями самих тензорных ядер и RT-ядер, Nvidia также представила то, что она называет параллелизмом второго поколения.
С Turing, GPU был ограничен одновременным выполнением конвейеров шейдеров и RT, в то время как любые рабочие нагрузки DLSS (Tensor) должны были идти дальше по конвейеру. С Ampere теперь можно выполнять операции шейдера, RT и DLSS одновременно, повышая производительность для конечного пользователя.
Используя Wolfenstein Youngblood в качестве примера, если бы Ampere попытался отрендерить кадр с трассировкой лучей с помощью программного обеспечения, без использования ядер RT или Tensor, Nvidia утверждает, что мы будем смотреть на время кадра в 37 мс, или около 27 кадров в секунду. Благодаря ядрам RT трассировку лучей значительно проще запускать, чем через программное обеспечение, поэтому время кадра можно сократить до 11 мс.
После добавления DLSS к рабочей нагрузке через ядро Tensor время рендеринга дополнительно сокращается до 7,5 мс.
Nvidia утверждает, что одновременное выполнение всех трех операций повысит производительность еще больше, с временем кадра 6,7 мс, или 149 кадров в секунду.
RTX IO - технология Nvidia
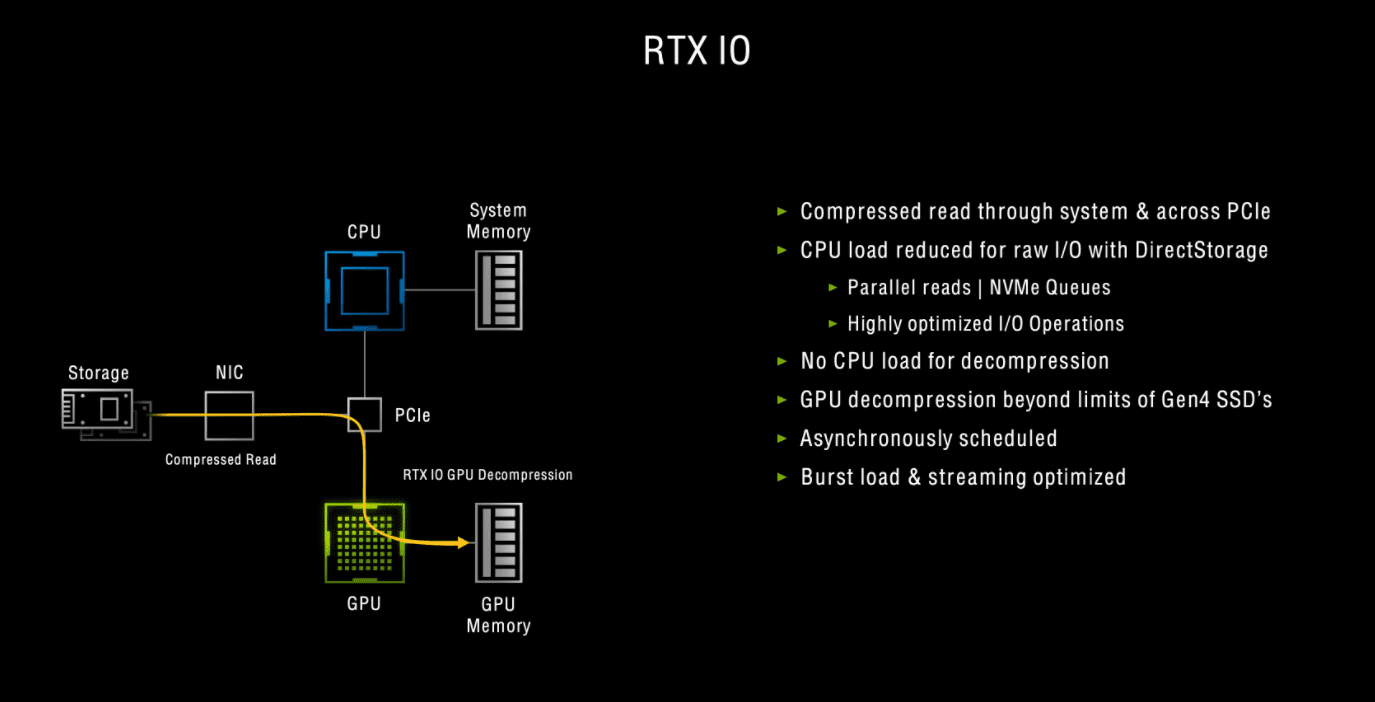
Последняя ключевая функция, которую мы хотим здесь затронуть - это RTX IO.
Nvidia объясняет это, указывая на постоянно растущие скорости SSD, которые теперь дико быстрее, чем традиционные HDD.
Однако увеличение скорости приводит к возникновению узких мест в традиционных подсистемах ввода-вывода, поэтому разработчики обращаются к методам сжатия без потерь.
Nvidia утверждает, что такие методы, выполняемые с помощью SSD PCIe Gen4, могут использовать «десятки CPU ядер», ограничивая производительность ввода-вывода и влияя на «потоковые системы следующего поколения, в которых нуждаются большие игры с открытым миром».
Решение - RTX IO. Это новый API, целью которого является обеспечение декомпрессии без потерь на базе графического процессора, перемещение работы с центрального процессора на графический процессор, который, как утверждает Nvidia, может обеспечить «достаточную мощность декомпрессии для поддержки даже нескольких SSD Gen4. Это может обеспечить скорость ввода-вывода более чем в 100 раз по сравнению с традиционными HDD и снизить загрузку процессора в 20 раз».
Самое интересное в том, что RTX IO требует специальной интеграции в игры со стороны разработчиков, поэтому мы не можем просто взять карту RTX и ускорить процесс в любой старой игре.
Тем не менее, Nvidia заявляет, что работает с Microsoft, чтобы обеспечить совместимость RTX IO с DirectStorage, поскольку, используя DirectStorage, игры следующего поколения смогут в полной мере использовать оборудование с поддержкой RTX IO, чтобы ускорить время загрузки и предоставить большие открытые миры? при этом снижая нагрузку на процессор».

Сейчас смотрят
































